[](https://www.apache.org/licenses/LICENSE-2.0)
# Exabyte Parser (ExaParser)
Exabyte parser is a python package to extract and convert materials modeling data (eg. Density Functional Theory, Molecular Dynamics) on disk to [ESSE/EDC](https://github.com/Exabyte-io/exabyte-esse) format.
## Functionality
As below:
- Extract structural information and material properties from simulation data
- Serialize extracted information according to [ESSE/EDC](https://github.com/Exabyte-io/exabyte-esse)
- Store serialized data on disk or remote databases
- Support for multiple simulation engines, including:
- [VASP](#links)
- [Quantum ESPRESSO](#links)
- others, to be added
The package is written in a modular way easy to extend for additional applications and properties of interest. Contributions can be in the form of additional [functionality](#todo-list) and [bug/issue reports](https://help.github.com/articles/creating-an-issue/).
## Installation
ExaParser can be installed as below.
1. Install [git-lfs](https://help.github.com/articles/installing-git-large-file-storage/) in order to pull the files stored on Git LFS.
1. Clone repository:
```bash
git clone git@github.com:Exabyte-io/exaparser.git
```
1. Install [virtualenv](https://virtualenv.pypa.io/en/stable/) using [pip](https://pip.pypa.io/en/stable/) if not already present:
```bash
pip install virtualenv
```
1. Create virtual environment and install required packages:
```bash
cd exaparser
virtualenv venv
source venv/bin/activate
export GIT_LFS_SKIP_SMUDGE=1
pip install -r requirements.txt
```
## Usage
1. Exaparser will look in the following locations for the `config` file, and use the first one it finds:
- The existing file in the root of this repository, *if installed as editable source*. This won't work for production installs, and is just for testing scenarios.
- Your user's home directory at `~/.exabyte/exaparser/config`
- A global system configuration at `/etc/exabyte/exaparser/config`
Copy the [`config`](config) file from the root of this repo to one of the above locations and edit it.
1. Edit the config file and adjust parameters as necessary. The most important ones are listed below.
- Add `ExabyteRESTfulAPI` to `data_handlers` parameters list (comma-separated), if not already present. This will enable upload the data into Exabyte.io account.
- New users can register [here](https://platform.exabyte.io/register) to obtain an Exabyte.io account.
- Set `owner_slug`, `project_slug`, `api_account_id`, and `api_auth_token` if `ExabyteRESTfulAPI` is enabled.
- See [RESTful API Documentation](https://docs.exabyte.io/rest-api/overview/) to learn how to obtain authentication parameters.
- Adjust `workflow_template_name` parameter in case a different template should be used.
- By default a [Shell Workflow](src/templates/shell.json) is constructed. See [Templates](#templates) section for more details.
- Adjust `properties` parameter to extract desired properties; all listed properties will be attempted for extraction.
1. Run the below commands to extract the data.
```bash
source venv/bin/activate
exaparser -w PATH_TO_JOB_WORKING_DIRECTORY
```
or just call exaparser with the explicit path to the virtualenv binary:
```bash
venv/bin/activate/exaparser -w PATH_TO_JOB_WORKING_DIRECTORY
```
## Tests
Run the following command to run the tests.
```bash
./run-tests.sh -p=PYTHON_BIN -v=VENV_NAME -t=TEST_TYPE
```
All the passed parameters are optional, with the defaults being `python3`, `venv`, and `unit`, respectively.
The script will create a virtual environment and populate it, so there's no need to create one manually for testing.
Note that the testing virtualenv uses the `requirements-dev.txt` file, where a production usage should use the `requirements.txt` file. This avoids installing test dependencies when not needed.
## Contribution
This repository is an [open-source](LICENSE.md) work-in-progress and we welcome contributions. We suggest forking this repository and introducing the adjustments there, the changes in the fork can further be considered for merging into this repository as explained in [GitHub Standard Fork and Pull Request Workflow](https://gist.github.com/Chaser324/ce0505fbed06b947d962).
## Architecture
The following diagram presents the package architecture.
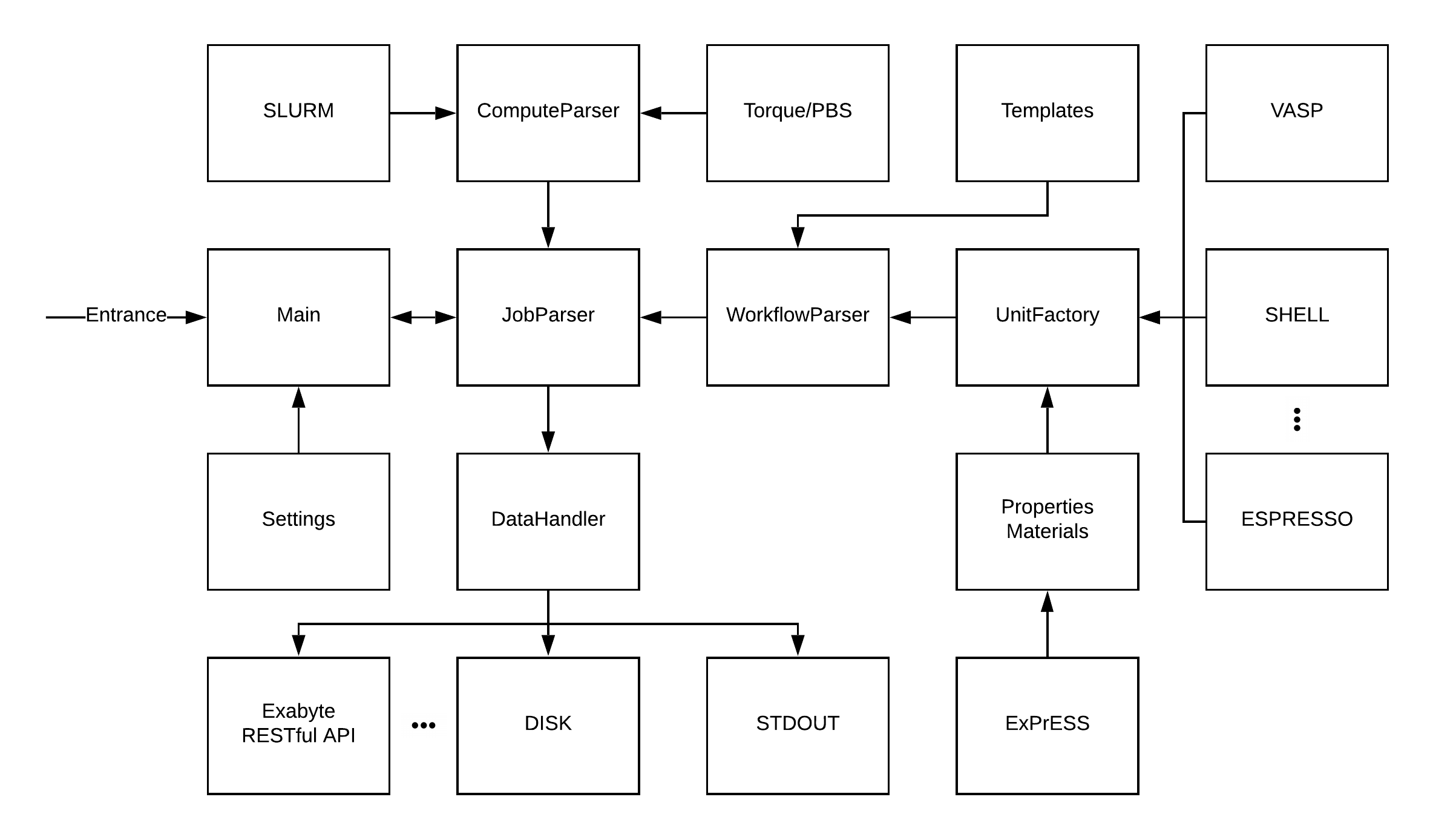
Here's an example flow of data/events:
- User invokes the parser with a path to a job working directory.
- The parser initializes a [`Job`](src/job/__init__.py) class to extract and serialize the job.
- Job class uses [`Workflow`](src/workflow/workflow.py) parser to extract and serialize the workflow.
- The Workflow is initialized with a [Template](#templates) to help the parser to construct the workflow.
- Users can add new templates or adjust the current ones to support complex workflows.
- Workflow parser iterates over the [Units](src/workflow/units) to extract
- application-related data
- input and output files
- materials (initial/final structures) and properties
- The job utilizes [Compute](src/job/compute) classes to extract compute configuration from the resource management system.
- Once the job is formed it is passed to [Data Handler](src/data/handlers) classes to handle data, e.g. storing data in Exabyte platform.
## Templates
Workflow templates are used to help the parser extracting the data as users follow different approaches to name their input/output files and organize their job directories. Readers are referred to [Exabyte.io Documentation](https://docs.exabyte.io/workflows/overview/) for more information about the structure of workflows. As explain above a [Shell Workflow Template](src/templates/shell.json) is used by default to construct the workflow. For each unit of the workflow one should specify `stdoutFile`, the relative path to the file containing the standard output of the job, `workDir`, the relative path to directory containing data for the unit and the name of `input` files.
## TODO List
Desirable features for implementation:
- Implement PBS/Torque and SLURM compute parsers
- Implement VASP and Espresso execution unit parsers
- Add other data handlers
- Add complex workflow templates
## Links
1. [Exabyte Source of Schemas and Examples (ESSE), Github Repository](https://github.com/exabyte-io/exabyte-esse)
1. [Vienna Ab-initio Simulation Package (VASP), official website](https://cms.mpi.univie.ac.at/vasp/)
1. [Quantum ESPRESSO, Official Website](https://www.quantum-espresso.org/)




