## Prosody features
```sh
prosody.py
```
Compute prosody features from continuous speech based on duration, fundamental frequency and energy.
Static or dynamic features can be computed:
Static matrix is formed with 103 features and include
Num Feature Description
--------------------------------------------------------------------------------------------------------------------------
Features based on F0
---------------------------------------------------------------------------------------------------------------------------
1-6 F0-contour Avg., Std., Max., Min., Skewness, Kurtosis
7-12 Tilt of a linear estimation of F0 for each voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
13-18 MSE of a linear estimation of F0 for each voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
19-24 F0 on the first voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
25-30 F0 on the last voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
--------------------------------------------------------------------------------------------------------------------------
Features based on energy
---------------------------------------------------------------------------------------------------------------------------
31-34 energy-contour for voiced segments Avg., Std., Skewness, Kurtosis
35-38 Tilt of a linear estimation of energy contour for V segments Avg., Std., Skewness, Kurtosis
39-42 MSE of a linear estimation of energy contour for V segment Avg., Std., Skewness, Kurtosis
43-48 energy on the first voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
49-54 energy on the last voiced segment Avg., Std., Max., Min., Skewness, Kurtosis
55-58 energy-contour for unvoiced segments Avg., Std., Skewness, Kurtosis
59-62 Tilt of a linear estimation of energy contour for U segments Avg., Std., Skewness, Kurtosis
63-66 MSE of a linear estimation of energy contour for U segments Avg., Std., Skewness, Kurtosis
67-72 energy on the first unvoiced segment Avg., Std., Max., Min., Skewness, Kurtosis
73-78 energy on the last unvoiced segment Avg., Std., Max., Min., Skewness, Kurtosis
--------------------------------------------------------------------------------------------------------------------------
Features based on duration
---------------------------------------------------------------------------------------------------------------------------
79 Voiced rate Number of voiced segments per second
80-85 Duration of Voiced Avg., Std., Max., Min., Skewness, Kurtosis
86-91 Duration of Unvoiced Avg., Std., Max., Min., Skewness, Kurtosis
92-97 Duration of Pauses Avg., Std., Max., Min., Skewness, Kurtosis
98-103 Duration ratios Pause/(Voiced+Unvoiced), Pause/Unvoiced, Unvoiced/(Voiced+Unvoiced),
Voiced/(Voiced+Unvoiced), Voiced/Puase, Unvoiced/Pause
---------------------------------------------------------------------------------------------------------------------------
The dynamic feature matrix is formed with 13 features computed for each voiced segment and contains:
- 1 Duration of the voiced segment
- 2-7. Coefficients of 5-degree Lagrange polynomial to model F0 contour
- 8-13. Coefficients of 5-degree Lagrange polynomial to model energy contour
Dynamic prosody features are based on
Najim Dehak, "Modeling Prosodic Features With Joint Factor Analysis for Speaker Verification", 2007
### Notes:
1. The fundamental frequency is computed the PRAAT algorithm. To use the RAPT method, change the "self.pitch method" variable in the class constructor.
2. When Kaldi output is set to "true" two files will be generated, the ".ark" with the data in binary format and the ".scp" Kaldi script file
### Runing
Script is called as follows
```sh
python prosody.py <file_or_folder_audio> <file_features> <static (true or false)> <plots (true or false)> <format (csv, txt, npy, kaldi, torch)>
```
### Examples:
Extract features in the command line
```sh
python prosody.py "../audios/001_ddk1_PCGITA.wav" "prosodyfeaturesAst.txt" "true" "true" "txt"
python prosody.py "../audios/001_ddk1_PCGITA.wav" "prosodyfeaturesUst.csv" "true" "true" "csv"
python prosody.py "../audios/001_ddk1_PCGITA.wav" "prosodyfeaturesUdyn.pt" "false" "true" "torch"
python prosody.py "../audios/" "prosodyfeaturesst.txt" "true" "false" "txt"
python prosody.py "../audios/" "prosodyfeaturesst.csv" "true" "false" "csv"
python prosody.py "../audios/" "prosodyfeaturesdyn.pt" "false" "false" "torch"
python prosody.py "../audios/" "prosodyfeaturesdyn.csv" "false" "false" "csv"
KALDI_ROOT=/home/camilo/Camilo/codes/kaldi-master2
export PATH=$PATH:$KALDI_ROOT/src/featbin/
python prosody.py "../audios/001_ddk1_PCGITA.wav" "prosodyfeaturesUdyn" "false" "false" "kaldi"
python prosody.py "../audios/" "prosodyfeaturesdyn" "false" "false" "kaldi"
```
Extract features directly in Python
```
from prosody import Prosody
prosody=Prosody()
file_audio="../audios/001_ddk1_PCGITA.wav"
features1=prosody.extract_features_file(file_audio, static=True, plots=True, fmt="npy")
features2=prosody.extract_features_file(file_audio, static=True, plots=True, fmt="dataframe")
features3=prosody.extract_features_file(file_audio, static=False, plots=True, fmt="torch")
prosody.extract_features_file(file_audio, static=False, plots=False, fmt="kaldi", kaldi_file="./test")
```
[Jupyter notebook](https://github.com/jcvasquezc/DisVoice/blob/master/notebooks_examples/prosody_features.ipynb)
#### Results:
Prosody analysis from continuous speech static
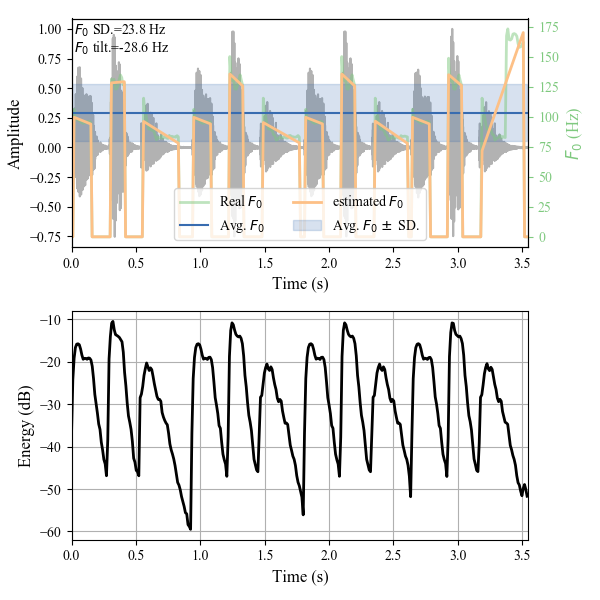
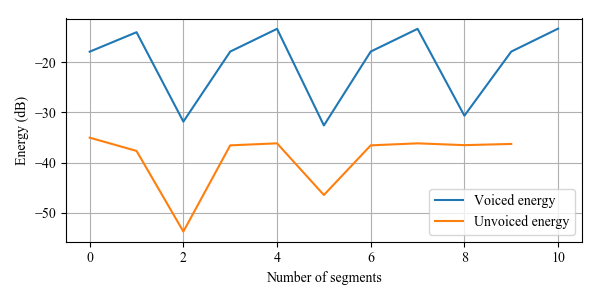
#### References
[[1]](http://ieeexplore.ieee.org/abstract/document/4291597/). N., Dehak, P. Dumouchel, and P. Kenny. "Modeling prosodic features with joint factor analysis for speaker verification." IEEE Transactions on Audio, Speech, and Language Processing 15.7 (2007): 2095-2103.
[[2]](http://www.sciencedirect.com/science/article/pii/S105120041730146X). J. R. Orozco-Arroyave, J. C. Vásquez-Correa et al. "NeuroSpeech: An open-source software for Parkinson's speech analysis." Digital Signal Processing (2017).




