# Dirba
Набор утилит для работы с ML моделями и их запуском в kafka.
## Содержание
1. [Установка](#установка)
2. [Работа с kafka](#работа-с-kafka)
1. [Что такое kafka](#что-такое-kafka)
2. [Consumer](#consumer)
1. [Конфигурация](#конфигурация)
3. [Producer](#producer)
4. [Runner для моделей](#runner-для-моделей)
1. [Model](#model)
2. [AbstractBaseKafkaRunner](#abstractBaseKafkaRunner)
3. [StrictRunner](#strictRunner)
4. [AbstractKafkaRunner](#abstractKafkaRunner)
3. [Запуск моделей через API](#запуск-моделей-через-API)
4. [Работа с каталогами](#работа-с-каталогами)
1. [Асинхронный API](#асинхронный-API)
2. [Синхронный API](#синхронный-API)
5. [Работа с источниками данных](#работа-с-источниками-данных)
6. [Валидация моделей](#валидация-моделей)
## Установка
Данный модуль подразумевает несколько вариантов установки
1. Стандартный `pip install dirba`. Подразумевает установку базовых библиотек. Позволяет пользоваться
каталогами и работать с источниками данных
2. Для работы с kafka. В таком случае `pip install dirba[kafka]` установит все необходимые зависимости
3. Для работы с валидацией потребуется выполнить `pip install dirba[validation]`
## Работа с kafka
### Что такое kafka
Apache Kafka — распределённый программный брокер сообщений. Основное его назначение – организация асинхронного
взаимодействия между различными сервисами с гарантиями доставки.
Если проще, то это промежуточное приложение, для общения различных приложений. Вполне логичный вопрос, который
может возникнуть – "зачем нужно это промежуточное приложение ?"
На деле, при реализации взаимодействия между различными приложениями, встаёт ряд проблем:
- что делать, если одно из приложений будет недоступно
- как распределить нагрузку между несколькими экземплярами приложения (для увеличения производительности)
- как хранить историю сообщений (чтобы можно было что-то отладить/посмотреть)
- как гарантировать обработку сообщения
При прямой схеме взаимодействия (например, по HTTP протоколу) решение вышеперечисленных проблем потребует
реализации дополнительного кода для каждого из приложений, что замедляет разработку и увеличивает вероятность
ошибок.
Kafka же, использует асинхронный подход во взаимодействии различных сервисов. Она принимает сообщение и хранит
его до тех пор, пока другое приложение не заберёт предназначенное для него сообщение.
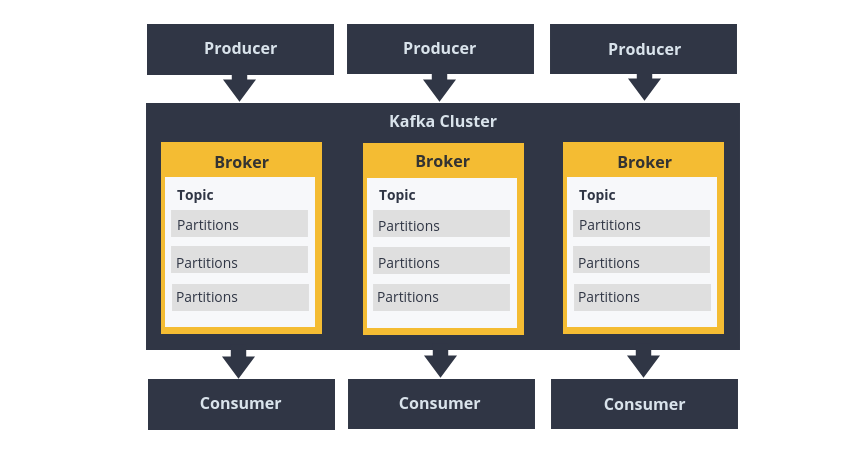
В такой схеме работы есть несколько ключевых понятий, которые стоит уточнить:
- **Producer** – внешнее приложение, *отправляющее* сообщение *в* kafka
- **Consumer** – внешнее приложение, *получающее* сообщение *из* kafka
- **Broker** – экземпляр (инстанс) приложения `Apache Kafka` (обычно их запускают от 3х штук, на разных
серверах, чтобы обеспечить бесперебойную работу (ведь без kafka приложение не смогут общаться)). В
совокупности превращаются в **Kafka Cluster**, с которым, фактически, и общаются ваши приложения (любое
приложение может переключиться на активный инстанс или работать сразу с несколькими)
- **Topic** – "тема", определённый ключ, с которым ассоциируются отправляемые в kafka сообщения. Этот же ключ
используется для получения сообщений
- **Partition** – "часть топика", логическая единица, для записи информации из *топика*. Кол-во партиций
связано с максимальным кол-вом приложений-consumer'ов (в одном *топике* не могут параллельно писать **
консьюмеров** больше, чем кол-во *партиций*). Как было сказано, партиция – логическая единица, которая могут
быть расположены в произвольном порядке на экземплярах приложения `Apache Kafka`
Итого мы имеем:
0. В рамках нашей системы у нас есть некоторый `Kafka Cluster`, к которому мы можем подключиться
1. У нас есть наше приложение-producer, отправляющее сообщения с данными в конкретный `Topic` на этом
кластере.
2. Другое приложение-consumer считывает сообщения из этого `Topic` и обрабатывает их согласно своей
бизнес-логике. При обработке сообщения приложением, оно подтверждает факт обработки, отправкой специального
commit-сигнала (как правило реализуется драйвером для kafka, но можно выполнять и самостоятельно).
#### Как consumer понимает, какое сообщение брать
Если вы внимательно прочитали главу выше, то вы должны были подметить, что там ни слова не сказано о том, как
консьюмер понимает, какие данные ему брать из kafka. Да, есть топик, которые разграничивает разные по виду
сообщения, но что если их в kafka накопилось несколько сотен или даже тысяч ? Для решения этой проблемы в
kafka существует механизм **групп** (`group`) и **сдвигов** (offset).
- Группа – это обобщение для определённого приложения. Подразумевает выдачу некоторого общего идентификатора.
Такой идентификатор называют `group_id`.
- Сдвиг – обозначение № сообщения, на котором находится та или иная группа.
Давайте рассмотрим следующий пример.
Мы организовываем работу в некотором банке. Понятно, что почти все приложения банка – высоконагруженные, а
потеря данных в них недопустима. Поэтому мы само собой вспоминаем про kafka и радостно её берём.
Для обработки всех транзакций (информации о платежах), мы выставляем 3 экземпляра написанного нами
приложения `acquiring`. Скорее всего это приложение представляет собой REST или gRPC API, которое
взаимодействует с клиентским приложением, принимает транзакцию и тут же отправляет её в kafka, **а это значит
что приложение acquiring – Producer**. В принципе, нам не важно, как приложение будет это делать, главное
чтобы приложения имели одну структуру, в независимости от экземпляра. Но на всякий случай мы **выдадим всем
экземплярам одинаковый group_id**, чтобы явно идентифицировать приложение.

После того как данные оказались в kafka, можно выдохнуть. Как минимум, мы уже их не потеряем, если что-то
навернётся. Значит, можно начать обрабатывать наши транзакции. Обработка транзакций – сложный процесс с кучей
логики, поэтому для них у нас поднято несколько экземпляров (на рисунке 2, а в реальности может быть и сильно
больше). Экземпляры приложения `business logic` **является Consumer'ами**, т.к. достают данные из kafka, мы их
тоже пометим отдельным `group_id`. В данном случае, одинаковый `group_id` **обязателен** для экземпляров **
одного и того же приложения**. Так мы гарантируем, что одно и то же сообщение не будет обработано более 1
раза.
Ну и осталось приложение `logger`, которое также **является Consumer'ом**. Для него у нас всего-лишь 1
экземпляр, т.к. логирование нам не к спеху и пригодится только при инцидентах. Ему мы **выставим
другой** `group_id`, отличный от `business logic`. Тем самым, мы и логгеру и бизнес логике позволим прочитать
одни и те же сообщения (ведь мы хотим все сообщения и обработать и залоггировать).
### Consumer
Для того чтобы реализовать свой Consumer, вам необходимо унаследовать абстрактный
класс `runners.kafka_runner.AbstractKafkaConsumer`.
Для этого вам необходимо:
- указать формат входной модели (подразумевается, что все сообщения в кафке хранятся в формате `json`).
Входная модель – `pydantic` модель, описывающая перечень полей в `json` сообщении. за входную модель
отвечает поле класса `InputModel`
- реализовать метод `on_startup`
- реализовать метод `process`
- ??????
- PROFIT!!!
Давайте посмотрим на пример такого сервиса
```python
import os
import aiomisc
import dirba.logging_utils
from dirba.runners import kafka as kafka_runner
class ExampleConsumer(kafka_runner.AbstractKafkaConsumer):
InputModel = kafka_runner.topic_schemas.LoaderMessage
async def on_startup(self):
print('started up')
async def process(self, message: InputModel):
print('message', message.uid_loaded_data, 'consumed')
if __name__ == '__main__':
config = kafka_runner.KafkaConfig(input_topic='loaded_data', group_id='example_dirba_consumer',
bootstrap_servers=os.environ['BOOTSTRAP_SERVERS'])
consumer = ExampleConsumer(config, from_topic_begin=False)
with aiomisc.entrypoint(consumer) as loop:
dirba.logging_utils.set_logging(sentry_url=os.environ['SENTRY_URL'])
loop.run_forever()
```
В данном случае у нас получится echo сервис, который будет выводить содержимое полученного из kafka сообщения.
#### Конфигурация
Для подключения к kafka вам необходимо заполнить `KafkaConfig`. Он содержит информацию о:
- топике `input_topic`, из которого будут считаны сообщения
- идентификаторе приложения `group_id` (должен быть уникален для каждого приложения)
- адресах подключения `bootstrap_servers` (`<ip1>:<port1>,<ip2>:<port2>`, т.е. адреса для подключения к
инстансам, через запятую)
Также, для отслеживания работы сервиса, необходимо сконфигурировать логирование с помощью
```
dirba.logging_utils.set_logging(sentry_url=os.environ['SENTRY_URL'])
```
Где, `os.environ['SENTRY_URL']` – url для отправки информации в sentry сервис (для PRODUCTION – обязательно,
для локальной разработки – по желанию)
#### Особенности сервиса
Что под капотом делает сервис:
- сериализует данные из kafka
- валидирует данные по указанной схеме
- обеспечивает работоспособность сервиса при ошибках.
- отправляет информацию об ошибках в sentry
- отсылает информацию о производительности в sentry
Что **не гарантирует сервис**:
- `commit` после каждого сообщения (атомарность для обработки сообщений)
- повторную обработку сообщения при ошибке
Основной кейс использования – потоковая обработка большого кол-ва сообщений, с допущением на частичную потерю
данных (в наших реалиях это менее 0,0001% от всех данных, но вы всё ещё можете повторить обработку, отследив
сообщения через sentry).
### Producer
По реализации, очень похож на Consumer~~, однако, как правило, сам по себе бесполезен~~.
Для запуска вам необходимо:
- указать формат выходной (output) модели (подразумевается, что все сообщения в кафке хранятся в формате json)
. Входная модель – pydantic модель, описывающая перечень полей в json сообщении. за выходную модель отвечает
поле класса OutputModel
- реализовать метод `on_startup`
- реализовать метод `pack` для сериализации данных в выходную модель
- переопределить метод `start`, добавив необходимую логику
```python
import os
from typing import Any
import aiomisc
import pydantic
import dirba.logging_utils
from dirba.runners import kafka as kafka_runner
class ExampleMessageSchema(pydantic.BaseModel):
id: int
message: str
class ExampleProducer(kafka_runner.AbstractKafkaProducer):
OutputModel = ExampleMessageSchema
def pack(self, data: Any) -> OutputModel:
return data
async def on_startup(self):
print('started up')
async def start(self, trigger_start=True):
await super(ExampleProducer, self).start(trigger_start=True)
for i in range(10):
message = ExampleMessageSchema(id=i, message=f'test {i}')
await self.send_message(message)
print('sent', message)
if __name__ == '__main__':
config = kafka_runner.KafkaConfig(None, group_id='example_dirba_producer',
bootstrap_servers=os.environ['BOOTSTRAP_SERVERS'],
output_topic='test__dirba')
producer = ExampleProducer(config)
with aiomisc.entrypoint(producer) as loop:
dirba.logging_utils.set_logging(sentry_url=os.environ['SENTRY_URL'])
loop.run_forever()
```
В данном примере мы просто немного поспамим сообщениями в kafka.
На самом деле класс `AbstractKafkaProducer` является скорее промежуточным (поэтому тут нужно переопределять
метод `start`) и предполагается, что он будет использоваться в множественном наследовании или будет запущен в
параллель с другим сервисом (смотри `/examples/example_producer.py` в репозитории).
Данный сервис лишь гарантирует robust'ное (устойчивое к сбоям) соединение с kafka, однако никоим образом не
обрабатывает ошибки, которые могут возникнуть в вашей логике.
Конфиг заполняется так же, как и в [producer'e](#producer), но вместо `input_topic`, необходимо
указать `output_topic`, в который будут отправляться сообщения.
### Runner для моделей
**Если** вы реализуете **ML** модель, **то вам сюда**
Runner'ы – семейство классов, обеспечивающие абстракцию различного уровня для потоковой работы с kafka (принял
сообщение, создал новое сообщение).
Все Runner'ы работают с базовой абстракцией – `Model`
#### Model
Model – сущность обеспечивающая обработку входных данных, с получением вероятностной оценки о принадлежности к
кому-либо классу. Иначе говоря – обёртка для классификаторов.
К сожалению, Model, имеет достаточно строгий API и приспособить его для другой задачи будет довольно
проблематично. Поэтому давайте посмотрим на то, как его реализовать.
##### AbstractProhibitedModel
`AbstractProhibitedModel` – частный случай `AbstractModel`. Единственное отличие – явная привязка к некоторому
каталогу. Подразумевается, что любая выдаваемая оценка от такой модели, должна быть для **категории,
существующей в** [каталоге](#работа-с-каталогами).
```python
class DamboInput(pydantic.BaseModel):
text: str
class DamboModel(AbstractProhibitedModel):
def __init__(self, category_catalog: CategoryCatalog):
super().__init__(category_catalog)
self.category_catalog.load_catalog_sync()
def predict(self, features: DamboInput) -> List[Predict]:
return [Predict(score=1, category=i) for i in self.category_catalog.catalog_values]
def preprocess(self, features: LoaderMessage) -> DamboInput:
return DamboInput(text='dambooooooooooooo')
def author(self) -> Author:
return Author(name='dambo', version='0.0.1')
```
Модель подразумевает отдельную функцию для предварительной обработки входного сообщения, и функцию по
получению вероятностей принадлежности к классу.
**Советы**
- если модель не отнесла входной материал к какой-либо категории, то нужно возвращать **пустой список**
- валидацию данных лучше оставить вне логики модели
- лучше избегать многопроцессорной обработки. Т.к. предполагается запуск через kafka, гораздо проще будет
увеличить кол-во инстансов, чем мучиться с последствиями многопоточности.
#### AbstractBaseKafkaRunner
Базовый класс для обработки данных из kafka моделью. Подразумевает следующий порядок работы:
- получение сообщения из kafka
- валидация по входной модели
- передача данных модели
- отправка результирующего сообщения в kafka
По своей сути – небольшая обёртка над [Consumer](#consumer) и [Producer](#producer), с добавлением вызова
модели
**Не стоит использовать данный класс для деплоя модели, если не хотите писать много кода**
```python
import os
import uuid
from typing import Optional
import aiomisc
from dirba.models.abc import Predict
from dirba.models.dambo import DamboModel
from dirba.runners.kafka_runners import AbstractBaseKafkaRunner, KafkaConfig
from dirba.runners.kafka_runners.topic_schemas import LoaderMessage, AnalysisMessage, AnalysisResult,
ModelOutput
from dirba.utils.catalogs import CategoryCatalog
class DamboBaseKafkaRunner(AbstractBaseKafkaRunner):
InputModel = LoaderMessage
OutputModel = AnalysisMessage
def pack_model_answer(self, message: InputModel, predict: Predict) -> Optional[OutputModel]:
input_data = message.dict(include={"uid_query", "query_id", "driver_id", "category_id", "type_id",
"uid_search", "uid_filter_link", "uid_loader",
"uid_loaded_data", "uid_analysis", })
model_answer = ModelOutput(category=predict.category, estimate=predict.score)
result = AnalysisResult(content_ref=message.result,
model=model_answer,
type_content=message.type_content)
packed = self.OutputModel(uid_analysis=uuid.uuid4(),
author=self.model.author(),
result=result,
**input_data)
return packed
def is_adorable(self, input_message: InputModel) -> bool:
return input_message.type_content == 'text'
async def on_startup(self):
print('started_up')
if __name__ == '__main__':
config = KafkaConfig(input_topic='loaded_data',
output_topic='dirba_simple_runner_test',
group_id='example_dirba_consumer',
bootstrap_servers=os.environ['BOOTSTRAP_SERVERS'])
category_catalog = CategoryCatalog(os.environ['CATALOG_URL'])
model = DamboModel(category_catalog)
runner = DamboBaseKafkaRunner(model, config, from_topic_begin=True)
with aiomisc.entrypoint(runner) as loop:
loop.run_forever()
```
#### StrictRunner
Тот же `AbstractRunner`, однако привязан к определённому формату данных. При получении сообщения делает
проверку на наличие категории в переданном каталоге.
**Не стоит использовать данный класс для деплоя модели, если не хотите писать много кода**
```python
import logging
import os
from random import random
from typing import List
import aiomisc
from dirba.models.abc import Predict
from dirba.models.dambo import DamboModel, DamboInput
from dirba.runners.kafka_runners import AbstractStrictBaseKafkaRunner, KafkaConfig
from dirba.utils.catalogs import CategoryCatalog
class DumbModel(DamboModel):
def predict(self, features: DamboInput) -> List[Predict]:
if random() > 0.5:
return [Predict(score=1, category=i) for i in self.category_catalog.catalog_values]
else:
return [Predict(score=1, category=-20)]
class DambKafkaRunner(AbstractStrictBaseKafkaRunner):
def is_adorable(self, input_message: AbstractStrictBaseKafkaRunner.InputModel) -> bool:
return input_message.type_content == 'text'
async def on_startup(self):
print('started_up')
if __name__ == '__main__':
config = KafkaConfig(input_topic='loaded_data',
output_topic='dirba_simple_runner_test',
group_id='example_dirba_consumer',
bootstrap_servers=os.environ['BOOTSTRAP_SERVERS'])
category_catalog = CategoryCatalog(os.environ['CATALOG_URL'])
model = DumbModel(category_catalog)
runner = DambKafkaRunner(model, config, from_topic_begin=True,
category_catalog=category_catalog,
produce_incorrect_categories=True)
with aiomisc.entrypoint(runner, log_level=logging.DEBUG) as loop:
loop.run_forever()
```
#### AbstractKafkaRunner
**Основной класс для использования**
Из коробки содержит:
- мониторинг через sentry
- выгрузка метрик в prometheus (роут `/metrics/`)
Вот пример его использования
```python
import os
import time
from random import random
from typing import Iterable
import aiomisc
import dirba
from dirba.models.abc import Predict
from dirba.models.dambo import DamboModel, DamboInput
from dirba.runners.kafka_runners import KafkaConfig
from dirba.runners.kafka_runners.runner import AbstractKafkaRunner
from dirba.utils.catalogs import CategoryCatalog
from dirba.utils.metrics.prometheus_exporter import PrometheusExporter
class ExampleRunner(AbstractKafkaRunner):
InputModel = AbstractKafkaRunner.InputModel
OutputModel = AbstractKafkaRunner.OutputModel
def is_adorable(self, input_message: InputModel) -> bool:
return input_message.type_content == 'text'
async def on_startup(self):
print('started up')
class DumbModel(DamboModel):
def predict(self, features: DamboInput) -> Iterable[Predict]:
# для использования дополнительных метрик они должны быть сконфигурированы
self.metric.add_label_values(ora='jojo', muda='dio')
time.sleep(1)
# в тех ситуациях, когда нужно прокинуть разные значения метрик для каждого predict'a,
# можно возвращать их с помощью генератора
for i in self.category_catalog.catalog_values:
if random() > 0.3:
self.metric.add_label_values(ora=f'jojo_{i}', muda='dio')
yield Predict(score=1, category=i)
if __name__ == '__main__':
config = KafkaConfig(input_topic='loaded_data',
output_topic='dirba_simple_runner_test',
group_id='example_dirba_runner',
bootstrap_servers=os.environ['BOOTSTRAP_SERVERS'])
# т.к. это "строгий" runner (как и модель), они должны взаимодействовать с каталогом
category_catalog = CategoryCatalog(os.environ['CATALOG_URL'])
model = DumbModel(category_catalog)
# from_topic_begin - отладочный вариант запуска. В проде он должен быть выставлен в False
runner = ExampleRunner(model, config, from_topic_begin=True, category_catalog=category_catalog)
# для прокидывания метрик также необходимо запустить экспортёр
exporter = PrometheusExporter(port=int(os.environ['PORT']), address='0.0.0.0')
# после инциализации runner'a можно сконфигурировать доп. набор метрик, при необходимости
runner.material_metric.register_labels('ora', 'muda')
# конфигурация логирования
dirba.logging_utils.set_logging(sentry_url=os.environ['SENTRY_URL'])
with aiomisc.entrypoint(runner, exporter) as loop:
loop.run_forever()
```
Из отличий – добавился ещё один сервис `PrometheusExporter`, который отвечает за выгрузку метрик. Метрики
можно получить по адресу, который был передан экспортёру, и роуту `/metrics/`. И да, экспортёр можно и не
запускать, но в таком случае и метрики выведены не будут. Однако это никоим образом не сломает раннер.
Также в примере продемонстрирована возможность добавления label'ов к метрике prometheus.
## Запуск моделей через API
WIP
## Работа с каталогами
Т.к. все модели ориентированы на получение вероятности принадлежности к категории, то мы где-то должны эти
категории брать. Хардкод – дело неблагодарное, поэтому у нас есть общий сервис, в котором содержится
информация о всех категориях. Раз это сервис, то, наверное, хотелось бы иметь обвязку для обращения к нему, да
ещё и с кэшом желательно.
Для этого у нас есть `utils.catalogs.abc.AbstractCatalog`. Сам класс представляет собой простенькую обвязку
для обращения к стороннему HTTP сервису.
Если вы захотите поработать именно с `AbstractCatalog`, то вам необходимо:
- Определить `pydantic` модель данных для данных каталога
- Переопределить метод `parse_catalog_response` для сериализации данных каталога в словарь, для последующей
обработки
Пример вы можете найти в обвязке вокруг конкретного каталога *категорий* в `utils.catalogs.category`.
У каталога есть 2 варианта API – синхронный и асинхронный.
### Асинхронный API
```python
import asyncio
import os
import time
import logging
from dirba.utils.catalogs import CategoryCatalog
logging.basicConfig(level=logging.DEBUG)
catalog = CategoryCatalog(os.environ['CATALOG_URL'])
async def async_example():
# демонстрация работы кэша
start_time = time.time()
count = 20
for i in range(count):
val = await catalog.get_value(catalog_id=14)
print(count, 'requests ended up in', time.time() - start_time, 'seconds')
print(val)
await catalog.get_catalog_data()
# в том числе и для несуществующих значений
for i in range(800, 810):
val = await catalog.get_value(catalog_id=i)
# все последующие обращения берутся из кэша
val = await catalog.get_value(catalog_id=i)
val = await catalog.get_value(catalog_id=i)
if __name__ == '__main__':
asyncio.run(async_example())
```
Основная функция для взаимодействия – `get_value`. Под капотом, она самостоятельно обновляет кэш значений из
каталога (если вы запрашиваете несуществующее значение, то каталоги будут обновлены, а дальше вступит в силу
кэш). Можно работать с результирующим словарём каталога напрямую *крайне не рекомендуется*.
И в синхронном варианте это будет выглядеть как-то так
### Синхронный API
```python
import os
import time
import logging
from dirba.utils.catalogs import CategoryCatalog
logging.basicConfig(level=logging.DEBUG)
catalog = CategoryCatalog(os.environ['CATALOG_URL'])
def sync_example():
# демонстрация работы кэша
start_time = time.time()
count = 20
for i in range(count):
val = catalog.get_value_sync(catalog_id=14)
print(count, 'sync requests ended up in', time.time() - start_time, 'seconds')
print(val)
# в том числе и для несуществующих значений
for i in range(800, 810):
val = catalog.get_value_sync(catalog_id=i)
# все последующие обращения берутся из кэша
val = catalog.get_value_sync(catalog_id=i)
val = catalog.get_value_sync(catalog_id=i)
if __name__ == '__main__':
sync_example()
```
Разницы по скорости между ними нет, однако в зависимости от вашего контекста исполнения, вам могут
понадобиться синхронный или асинхронный варианты.
Более подробную информацию вы можете найти в документации методов и самого класса
## Работа с источниками данных
Если вы разрабатываете ML модель, то у вас скорее всего встанет ещё один вопрос, как достать данные для их
прогона через модель, ведь вам приходит лишь идентификатор.
Для работы с данными есть набор классов в `utils.data_loader`. Останавливаться на подробностях
имплементации `AbstractDataLoader` смысла не вижу (т.к. все реализации уже готовы). Скажу лишь, что из коробки
там прописана `retry` политика для HTTP запросов, чтобы вам поменьше страдать.
Используются классы для данных максимально просто:
- выбираете нужный по названию сущности
- указываете URL до сервиса
- получаете данные по идентификатору сущности, который вы получили
```python
import os
from dirba.utils.data_loader import TextLoader, HtmlLoader, ImageLoader
if __name__ == '__main__':
service_url = os.environ['SERVICE_URL']
text_loader = TextLoader(service_url)
print(text_loader.get_content(entity_id=1))
html_loader = HtmlLoader(service_url)
print(html_loader.get_content(entity_id=1))
image_loader = ImageLoader(service_url)
image = image_loader.get_content(entity_id=1)
with open('./tempo.jpg', 'wb') as f:
f.write(image[1].content)
```
## Валидация моделей
WIP




