<p align="center">
<img height="50%" width="50%" src="https://github.com/SAP/contextual-ai/blob/master/imgs/logo.png?raw=true">
</p>
Contextual AI
==============
[](https://travis-ci.com/SAP/contextual-ai)
[](https://contextual-ai.readthedocs.io/en/latest/?badge=latest)
[](https://coveralls.io/github/SAP/contextual-ai?branch=master)
[](https://lgtm.com/projects/g/SAP/contextual-ai/context:python)

[](https://badge.fury.io/py/contextual-ai)
[](https://opensource.org/licenses/Apache-2.0)
[](https://gitter.im/SAP/contextual-ai?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge)
Contextual AI adds explainability to different stages of machine learning pipelines - data, training, and inference - thereby addressing the trust gap between such ML systems and their users.
## 🖥 Installation
Contextual AI has been tested with Python 3.6, 3.7, and 3.8. You can install it using pip:
```
$ pip install contextual-ai
```
### Building locally
````
$ sh build.sh
$ pip install dist/*.whl
````
## ⚡️ Quickstart 1 - Explain the predictions of a model
In this simple example, we will attempt to generate explanations for some ML model trained on 20newsgroups, a text classification dataset. In particular, we want to find out which words were important for a particular prediction.
```python
from pprint import pprint
from sklearn import datasets
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
# Main Contextual AI imports
import xai
from xai.explainer import ExplainerFactory
# Train on a subset of the 20newsgroups dataset (text classification)
categories = [
'rec.sport.baseball',
'soc.religion.christian',
'sci.med'
]
# Fetch and preprocess data
raw_train = datasets.fetch_20newsgroups(subset='train', categories=categories)
raw_test = datasets.fetch_20newsgroups(subset='test', categories=categories)
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(raw_train.data)
y_train = raw_train.target
X_test = vectorizer.transform(raw_test.data)
y_test = raw_test.target
# Train a model
clf = MultinomialNB(alpha=0.1)
clf.fit(X_train, y_train)
############################
# Main Contextual AI steps #
############################
# Instantiate the text explainer via the ExplainerFactory interface
explainer = ExplainerFactory.get_explainer(domain=xai.DOMAIN.TEXT)
# Build the explainer
def predict_fn(instance):
vec = vectorizer.transform(instance)
return clf.predict_proba(vec)
explainer.build_explainer(predict_fn)
# Generate explanations
exp = explainer.explain_instance(
labels=[0, 1, 2], # which classes to produce explanations for?
instance=raw_test.data[9],
num_features=5 # how many words to show?
)
print('Label', raw_train.target_names[raw_test.target[0]], '=>', raw_test.target[0])
pprint(exp)
```
#### Input text:
```
From: creps@lateran.ucs.indiana.edu (Stephen A. Creps)\nSubject: Re: The doctrine of Original Sin\nOrganization: Indiana University\nLines: 63\n\nIn article <May.11.02.39.07.1993.28331@athos.rutgers.edu> Eugene.Bigelow@ebay.sun.com writes:\n>>If babies are not supposed to be baptised then why doesn\'t the Bible\n>>ever say so. It never comes right and says "Only people that know\n>>right from wrong or who are taught can be baptised."\n>\n>This is not a very sound argument for baptising babies
...
```
#### Output explanations:
```
Label soc.religion.christian => 2
{0: {'confidence': 6.79821e-05,
'explanation': [{'feature': 'Bible', 'score': -0.0023500809763485468},
{'feature': 'Scripture', 'score': -0.0014344577715211986},
{'feature': 'Heaven', 'score': -0.001381196356886895},
{'feature': 'Sin', 'score': -0.0013723724408794883},
{'feature': 'specific', 'score': -0.0013611914394935848}]},
1: {'confidence': 0.00044,
'explanation': [{'feature': 'Bible', 'score': -0.007407412195931125},
{'feature': 'Scripture', 'score': -0.003658367757678809},
{'feature': 'Heaven', 'score': -0.003652181996607397},
{'feature': 'immoral', 'score': -0.003469502264458387},
{'feature': 'Sin', 'score': -0.003246609821338066}]},
2: {'confidence': 0.99948,
'explanation': [{'feature': 'Bible', 'score': 0.009736539971486623},
{'feature': 'Scripture', 'score': 0.005124375636024145},
{'feature': 'Heaven', 'score': 0.005053514624616295},
{'feature': 'immoral', 'score': 0.004781252244149238},
{'feature': 'Sin', 'score': 0.004596128058053568}]}}
```
## ⚡️ Quickstart 2 - Generate an explainability report
Another functionality of `contextual-ai` is the ability to generate PDF reports that compile the results of data analysis, model training, feature importance, error analysis, and more. Here's a simple example where we provide an explainability report for the [Titanic](https://www.kaggle.com/c/titanic) dataset. The full tutorial can be found [here](https://contextual-ai.readthedocs.io/en/latest/tutorials/compiler/tutorial_titanic2.html).
```python
import os
import sys
from pprint import pprint
from xai.compiler.base import Configuration, Controller
json_config = 'basic-report-explainer.json'
controller = Controller(config=Configuration(json_config))
pprint(controller.config)
```
The `Controller` is responsible for ingesting the configuration file `basic-report-explainer.json` and parsing the specifications of the report. The configuration file looks like this:
```
{'content_table': True,
'contents': [{'desc': 'This section summarized the training performance',
'sections': [{'component': {'attr': {'labels_file': 'labels.json',
'y_pred_file': 'y_conf.csv',
'y_true_file': 'y_true.csv'},
'class': 'ClassificationEvaluationResult',
'module': 'compiler',
'package': 'xai'},
'title': 'Training Result'}],
'title': 'Training Result'},
{'desc': 'This section provides the analysis on feature',
'sections': [{'component': {'_comment': 'refer to document '
'section xxxx',
'attr': {'train_data': 'train_data.csv',
'trained_model': 'model.pkl'},
'class': 'FeatureImportanceRanking'},
'title': 'Feature Importance Ranking'}],
'title': 'Feature Importance Analysis'},
{'desc': 'This section provides a model-agnostic explainer',
'sections': [{'component': {'attr': {'domain': 'tabular',
'feature_meta': 'feature_meta.json',
'method': 'lime',
'num_features': 5,
'predict_func': 'func.pkl',
'train_data': 'train_data.csv'},
'class': 'ModelAgnosticExplainer',
'module': 'compiler',
'package': 'xai'},
'title': 'Result'}],
'title': 'Model-Agnostic Explainer'},
{'desc': 'This section provides the analysis on data',
'sections': [{'component': {'_comment': 'refer to document '
'section xxxx',
'attr': {'data': 'titanic.csv',
'label': 'Survived'},
'class': 'DataStatisticsAnalysis'},
'title': 'Simple Data Statistic'}],
'title': 'Data Statistics Analysis'}],
'name': 'Report for Titanic Dataset',
'overview': True,
'writers': [{'attr': {'name': 'titanic-basic-report'}, 'class': 'Pdf'}]}
```
The `Controller` also triggers the rendering of the report:
```python
controller.render()
```
Which produces [this PDF report](https://github.com/SAP/contextual-ai/blob/master/tutorials/compiler/titanic2/titanic-basic-report.pdf) which visualizes data distributions, training results, feature importances, local prediction explanations, and more!
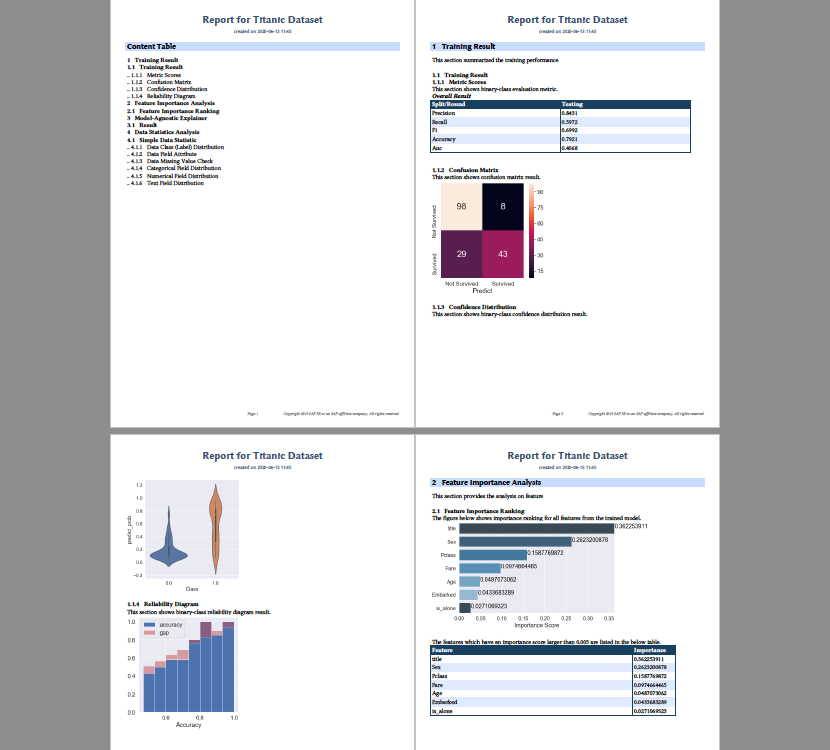
## 🚀 What else can it do?
Contextual AI spans three pillars, or scopes, of explainability, each addressing a different stage of a machine learning solution's lifecycle. We provide several features and functionalities for each:
### Pre-training (Data)
* Distributional analysis of data and features
* Data validation
* [Tutorial](https://contextual-ai.readthedocs.io/en/latest/data_module_tutorial.html)
### Training evaluation (Model)
* Training performance
* Feature importance
* Per-class explanations
* Simple error analysis
* [Tutorial](https://contextual-ai.readthedocs.io/en/latest/training_module_tutorial.html)
### Inference (Prediction)
* Explanations per prediction instance
* [Tutorial](https://contextual-ai.readthedocs.io/en/latest/inference_module_tutorial.html)
We currently support the following explainers for each data type:
**Tabular**:
* [LIME Tabular Explainer](https://lime-ml.readthedocs.io/en/latest/lime.html#module-lime.lime_tabular)
* [SHAP Kernel Explainer](https://shap.readthedocs.io/en/latest/#shap.KernelExplainer)
**Text**:
* [LIME Text Explainer](https://lime-ml.readthedocs.io/en/latest/lime.html#module-lime.lime_text)
Looking to integrate your own explainer into contextual AI? Look at the [following documentation](https://contextual-ai.readthedocs.io/en/latest/inference_module.html) to see how you can use our `AbstractExplainer` class to create your own explainer that satisfies our interface!
### Formatter/Compiler
* Produce PDF/HTML reports of outputs from the above using only a few lines of code
* [Tutorial](https://contextual-ai.readthedocs.io/en/latest/compiler_module_tutorial.html)
## 🤝 Contributing
We welcome contributions of all kinds!
- Reporting bugs
- Requesting features
- Creatin pull requests
- Providing discussions/feedback
Please refer to `CONTRIBUTING.md` for more.
### Contributors
* [Sean Saito](https://github.com/seansaito)
* [Wang Jin](https://github.com/wangjin1024)
* [Chai Wei Tah](https://github.com/postalC)
* [Ni Peng](mailto:peng.ni@sap.com)
* Amrit Raj
* Karthik Muthuswamy




