# K Immediate Neighbors
K Immediate Neighbors or **KIN** is a machine learning algorithm inspired by KNN (K Nearest Neighbors) which has been adjusted to graph-structured data. Instead of asking k nearest neighbors of a test *sample* in euclidean space about the label, it asks the k immidiate neighbors of a test *node* in graph.\
You can use KIN in problems where it is possible to **model your data as graph** and **classify the nodes**.
## Installation:
You can install the package using pip with the following commad:
```
pip install GML_KIN
```
## Usage:
```
class KIN(k=0, num_edge_types=1, edge_weights=[1], validation_size=0.1, random_state=42)
```
### Parameters:
**k: *int, default=0***\
Maximum number of immediate neighbors to ask about the label. In case of num_neighbors > k, asks the ones with the highest weight on their respective edge.\
If k=0, asks all immediate neighbors.
**num_edge_types: *int, default=1***\
You can define multiple edge types with KIN. For example if you want to classify books, you might have edge types: same_author, same_genre, same_price_range, belonging_to_same_series, ...\
This parameter represents the count of your different edge types.\
Note that later these types will be identified with numbers ranging from 0 to num_edge_types-1
**edge_weights: *list, default=[1]***\
This shows the importance of different edge types in terms of classification.\
If you leave this parameter with its default value, KIN will learn these weights based on your training input graph. Its highly recommended to leave this parameter *as is*, but if you want to input customized weights of importance for your edge types feel free to use it.\
Note that each weight is a float, len(edge_weights) should be equal to num_edge_types and sum(edge_weights) should be 1.0\
**Do not confuse this with actual weights of edges.**
**validation_size: *float, default=0.1***\
This parameter will be ignored if you use *edge_weights* manually. If not, will be used to select a portion of nodes to evaluate edge_weights based on your training input graph. Gives best answer when set to 1.0 and applied to a balanced dataset.
**random_state: *int, default=42***\
Controls the pseudo random number generation for choosing the validation nodes.
### Methods:
```
fit(X_train, y_train)
```
Fits the KIN model according to the given training data.\
***X_train:*** **3 dimensional list**, second dimension represents nodes and the third one represents the edges. The first 2 dimensional list represents the node with index=0, the second one represents the node with index=1 and so on. Inside these 2 dimensional lists which represent nodes, there are 1 dimensional lists which represent edges connected from the respective node to the other nodes in this format: [destination_node, edge_weight, edge_type]\
Overall, the shape of X_train looks like this: (N, Mi, 3)\
N: Total count of nodes.\
Mi: Count of exiting edges from Node with index i.\
**Please refer to the example below for better understanding.**\
Note that if you want to implement an undirected edge between nodes p and q, you should create one edge from p to q and one edge from q to p.\
***y_train:*** **1 dimensional list** representing the respective labels of nodes in X_train. Please use numbers as representatives.
```
predict(X_test)
```
Performs classification on samples in X_test.
X_test has same the structure as X_train.
```
score(X_test, y_test, measure='accuracy')
```
Returns the accuracy on the given test data and labels.\
In this version only *accuracy* is supported, I'll add more measures in later releases.
## Example:
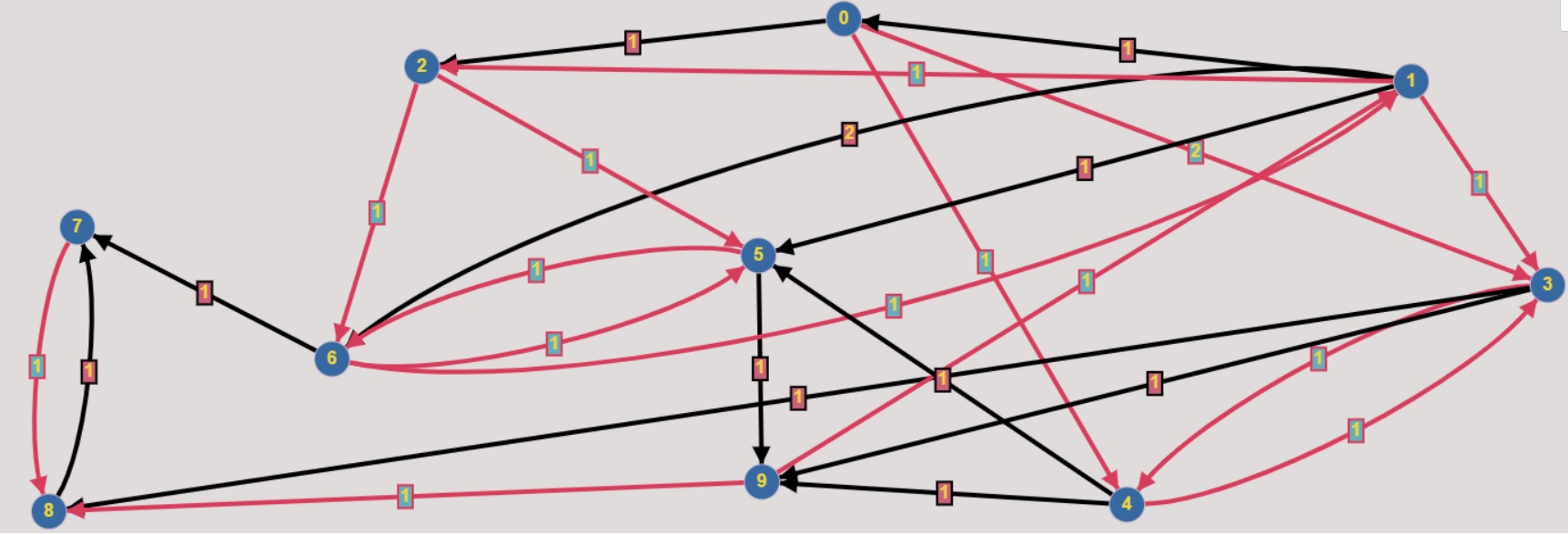
Black edges are type 0.\
You can see the code represtation of this graph in the section below.
#### Sample code:
```python
from GML_KIN import KIN
X_train = [[[2, 1, 0], [3, 2, 1], [4, 1, 1]], #node 0
[[0, 1, 0], [2, 1, 1], [5, 1, 0], [6, 2, 0]], #node 1
[[5, 1, 1], [6, 1, 1]], #node 2
[[4, 1, 1], [8, 1, 0], [9, 1, 0]], #node 3
[[3, 1, 1], [5, 1, 0], [9, 1, 0]], #node 4
[[6, 1, 1], [9, 1, 0]], #node 5
[[1, 1, 1], [5, 1, 1], [7, 1, 0]], #node 6
[[8, 1, 1]], #node 7
[[7, 1, 0]], #node 8
[[1, 1, 1], [8, 1, 1]]] #node 9
y_train = [0, 1, 1, 0, 0, 1, 1, 0, 0, 1]
X_test = [[[1, 1, 1], [7, 1, 0]], #test node 10
[[0, 1, 1], [4, 1, 0], [9, 1, 1]]] #test node 11
y_test = [1, 0]
kin_clf = KIN(k=2, num_edge_types=2, validation_size=0.3, random_state=42)
kin_clf.fit(X_train, y_train)
print('Accuracy: ', kin_clf.score(X_test, y_test, measure='accuracy'))
```




