# AutoEnsembler
This is an AutoEnsembler package, it helps you to find the best ensemble model for Classification and Regression problem. As we know that every model gives best at certain type/part of data , by assuming this, AutoEnClassifer and AutoEnRegressor has been built on top of LogisticRegression/Lasso, SVC/SVR, RandomForestClassifier/RandomForestRegressor, AdaBoostClassifer/AdaBoostRegressor, LGBMClassifier/LGBMRegressor, XGBClassifier/XGBRegressor and KNeighborsClassifier/KNeighborsRegressor.
### What's new ?
- Changed GridSearch attribute to search and now it can take values 'random', 'grid', False.
### Uniqueness
- In AutoEnClassifer, you can pass a parameter that you want to optimize, i.e. 'FN' / 'FP'
- While training, by default it will split the data into training data and validation data by 0.2 (you can also specify) and it will show you the accuracy_score/r2_score (with respect to each model you selected and of AutoEnClassifer/AutoEnRegressor) on validation data
- While initiating the model you can also specify which models should be used for ensembling and what type of search you want to use.
### Motivation
I participated in various competitions of Data Science & Machine Learning and I learned many things from it. As my contribution towards this community, I'm sharing this AutoEnsembler package with you all.
### When to use ?
- If you want to build Robust Model with mean less time.
- When you have small or medium size data.
- If you have large size data then set search to False.
### Installation
```markdown
pip install AutoEnsembler
```
### How to use ?
#### AutoEnClassifier
After installing, you can import this, as shown below. By default LogisticRegression/Lasso, RandomForestClassifier/RandomForestRegressor and LGBMClassifier/LGBMRegressor is selected. While fitting the model, validation_split is set to 0.25 (by default is 0.2). You can also see the accuracy_score/r2_score of individual model and of AutoEn model on validation_split data and you can also see the weight used for individual models for prediction.
Note :- (Recommended) Create your own validation data and this validation data should have same distribution as test data for best results on test data.
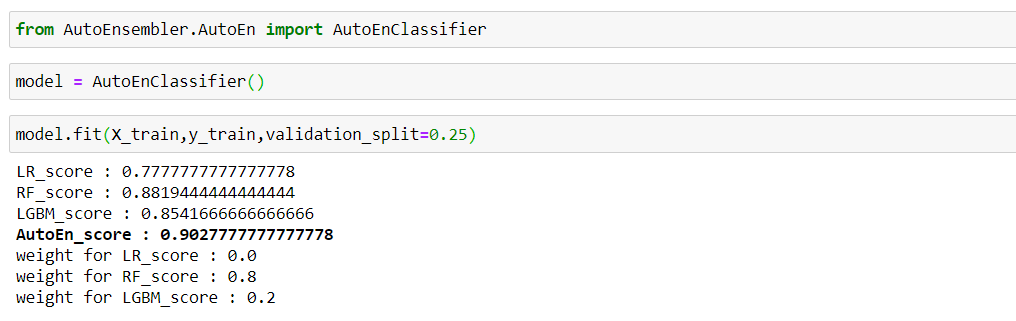
As you can see below, rest all the models are now set to True with respect to each model name and search is set to 'grid' (by default is 'random').
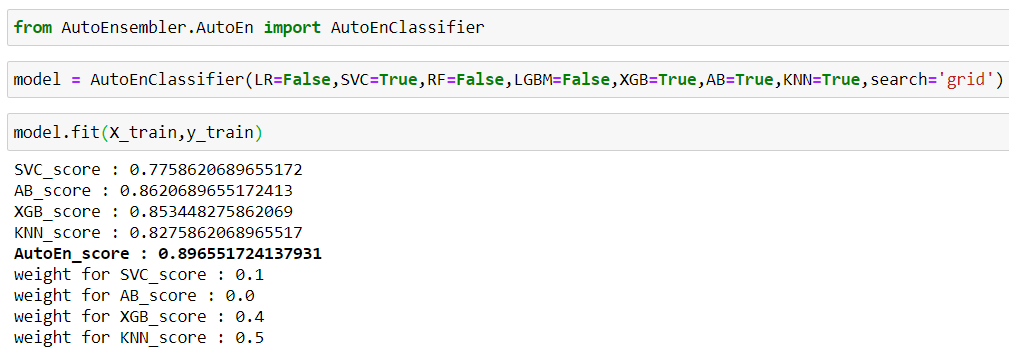
Now, search is set to 'random' and passed validation data to it and now the score will compute on validation_data.
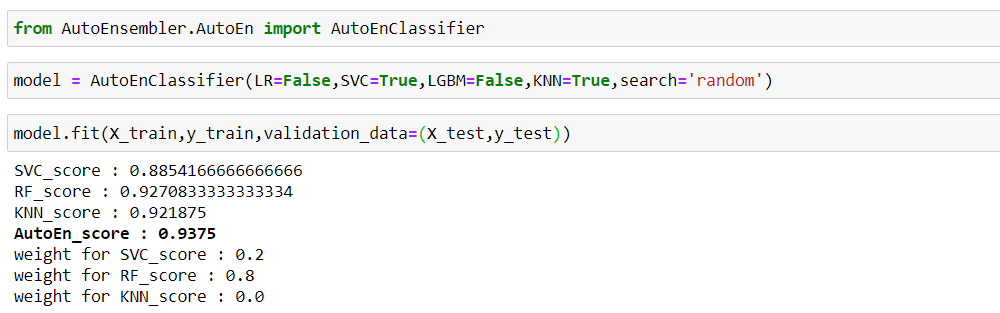
Below, optimize is set to 'FP', to optimizing the 'FP' i.e. False Positive
Note:- Here 'FP' count is optimized with respect to validation data and on your test data it will be more or less equal, depending upon the size.
You may think how it is optimized, while ensembling, one may get multiple models with same accuracy, from that it will select least 'FN'/'FP' as you specify.
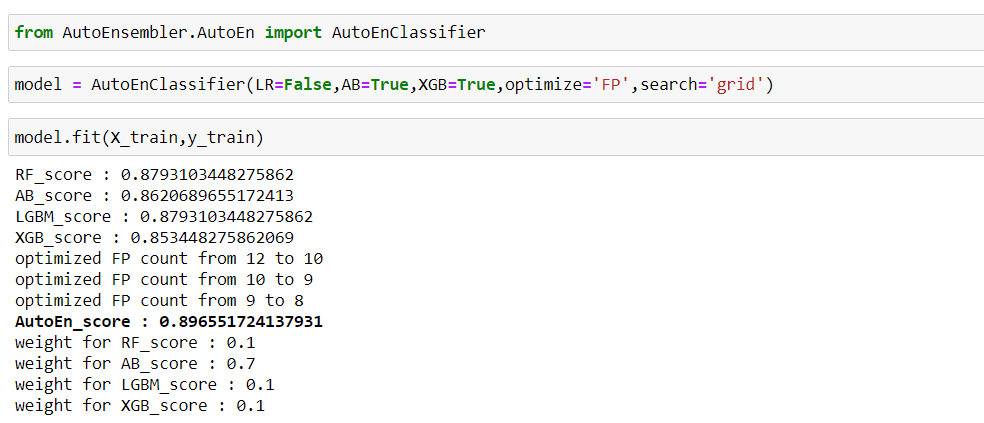
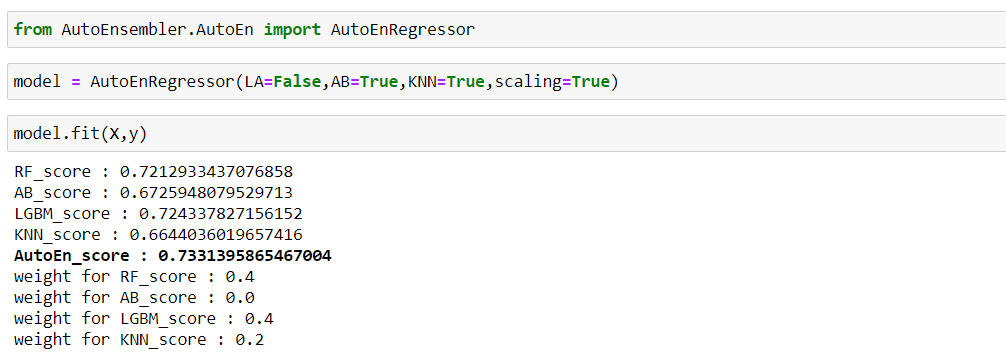
#### AutoEnRegressor
As you can see with four models, AutoEnRegressor reached near to 0.73 r2_score. By default scaling is set to True in both AutoEnClassifier and AutoEnRegressor
Almost all features are similar with respect to AutoEnClassifier.
Reminder :- (Recommended) Create your own validation data and this validation data should follow same distribution as test data for best results on test_data.
### To Do
- To include class_weight attribute.
## Bug / Feature Request
If you find a bug, kindly open an issue [here](https://github.com/nileshchilka1/AutoEnsembler/issues/new/choose) by including your search query and the expected result.
If you would like to request a new function, feel free to do so by opening an issue [here](https://github.com/nileshchilka1/AutoEnsembler/issues/new/choose). Please include sample queries and their corresponding results.
### Want to Contribute
If you are strong in OOPS concept/Machine Learning, please feel free to contact me.
Email :- nileshchilka1@gmail.com
### Happy Learning!!




